Acessando APIs com R: GitHub - Parte 1
By Beatriz Milz in Portugues API purrr httr web-scraping git github
February 19, 2022
Este post foi originalmente publicado no Blog da Curso-R.
Introdução
Esse post faz parte de uma série sobre acesso à APIs com R! O primeiro post foi uma introdução sobre como acessar APIs com R.
Neste post mostraremos um exemplo usando a API do GitHub.
O GitHub é uma plataforma onde conseguimos hospedar repositórios (pastas com nossos códigos e arquivos) com controle de versão usando o Git, e podemos fazer muitas coisas utilizando a sua API. E como dissemos no post anterior: “o primeiro passo para acessar qualquer API é procurar uma documentação”. A boa notícia é que a documentação da API do GitHub está disponível em Português e é bem detalhada!
Existem muitas ações possíveis utilizando essa API. O que escolhemos para esse exemplo é buscar os repositórios que pertencem à uma organização.
Segundo a documentação, para consultar os repositórios que pertencem à organização octokit, podemos utilizar a seguinte busca:
GET /orgs/octokit/repos
O equivalente a isso usando o pacote httr é:
# url_base - nunca muda na mesma API
url_base <- "https://api.github.com"
# endpoint - é o que muda o resultado
endpoint <- "/orgs/octokit/repos"
# precisamos colar os textos para criar o link
u_github <- paste0(url_base, endpoint)
# ver como o texto ficou colado
# u_github
# > "https://api.github.com/orgs/octokit/repos"
# fazer a requisição do tipo GET
r_github <- httr::GET(u_github)
r_github
Response [https://api.github.com/orgs/octokit/repos]
Date: 2022-03-02 17:04
Status: 200
Content-Type: application/json; charset=utf-8
Size: 181 kB
[
{
"id": 417862,
"node_id": "MDEwOlJlcG9zaXRvcnk0MTc4NjI=",
"name": "octokit.rb",
"full_name": "octokit/octokit.rb",
"private": false,
"owner": {
"login": "octokit",
"id": 3430433,
...
Podemos acessar o resultado usando a função httr::content(), porém não vamos colocar o resultado no post pois ficaria muito longo.
# httr::content(r_github)
O que é o pacote gh?
O pacote gh permite acessar a API do GitHub. A lógica mostrada anteriormente se aplica para esse pacote também: precisaremos consultar a documentação para verificar como fazer alguma tarefa com a API.
Primeiro exemplo com o pacote gh
Neste exemplo, vamos buscar as informações sobre os repositórios que são organização Curso-R no GitHub, gerar um dataframe, e ao final fazer uma visualização simples.
Informações gerais da organização Curso-R
Podemos buscar informações sobre a organização da Curso-R no GitHub:
gh_curso_r <- gh::gh("GET /orgs/{org}",
org = "curso-r")
A sintaxe do pacote gh é similar ao
glue. Quando queremos buscar uma informação que está em uma variável (no caso “curso-r”), colocamos os {variavel} no primeiro argumento e escrevemos variavel= nos argumentos seguintes.
Como vimos, o resultado é uma lista. Para consultar o número de repositórios públicos, podemos usar o $ para acessar essa informação dentro da lista:
gh_curso_r$public_repos
[1] 304
Olha só, a Curso-R tem atualmente 304 repositórios públicos no GitHub! Temos muitos repositórios pois criamos um diferente para cada curso, para que quem faz aula com a gente tenha sempre um lugar para olhar todos os materiais, de forma organizada e independente.
Acessando informações de repositórios
Podemos buscar informações sobre os repositórios que pertencem à organização Curso-R no GitHub:
repositorios_cursor <- gh::gh("GET /orgs/{org}/repos", org = "curso-r")
# A classe que retorna é uma lista
class(repositorios_cursor)
[1] "gh_response" "list"
# É uma lista grande!
length(repositorios_cursor)
[1] 30
Esse código retornou informações de apenas 30 repositórios. Portanto, precisamos repetir o processo para obter informações de todos os repositórios.
Iterando com purrr e o pacote gh
A documentação do pacote aponta que é possível buscar informações de 100 repositórios por vez. Se queremos buscar todos os repositórios, primeiro precisamos calcular quantas vezes vamos repetir o processo todo:
numero_repos_publicos <- gh_curso_r$public_repos
# podemos buscar 100 repositórios por vez,
# então podemos dividir o numero de repositorios
# por 100, e arredondar "para cima"
# (é para isso que a função ceiling() serve!)
numero_paginas <- ceiling(numero_repos_publicos/100)
numero_paginas
[1] 4
Precisaremos repetir 4 vezes! Agora podemos usar a função purrr::map() para repetir o acesso à API quantas vezes forem necessárias para obter as informações de todos os repositórios da Curso-R:
repos_cursor <- purrr::map(1:numero_paginas,
.f = ~gh::gh(
"GET /orgs/{org}/repos",
org = "curso-r", # organizacao
type = "public", # tipo de repositorio
sort = "updated", # forma de ordenar a busca
per_page = 100, # numero de resultados por pagina
page = .x # numero da pagina que será substituido
))
O resultado ainda é uma lista… podemos usar a magia do pacote purrr e transformar essa lista em um dataframe:
lista_repos <- repos_cursor |>
purrr::flatten() |>
purrr::map(unlist, recursive = TRUE) |>
purrr::map_dfr(tibble::enframe, .id = "id_repo") |>
tidyr::pivot_wider() |>
janitor::clean_names()
lista_repos
# A tibble: 304 × 108
id_repo id node_id name full_name private owner_login owner_id
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 1 249453848 MDEwOlJlcG9za… tree… curso-r/… FALSE curso-r 10060716
2 2 407944311 MDEwOlJlcG9za… gati… curso-r/… FALSE curso-r 10060716
3 3 273357487 MDEwOlJlcG9za… lives curso-r/… FALSE curso-r 10060716
4 4 166050452 MDEwOlJlcG9za… zen-… curso-r/… FALSE curso-r 10060716
5 5 431975866 R_kgDOGb9tug 2022… curso-r/… FALSE curso-r 10060716
6 6 315779098 MDEwOlJlcG9za… tril… curso-r/… FALSE curso-r 10060716
7 7 431987842 R_kgDOGb-cgg 2022… curso-r/… FALSE curso-r 10060716
8 8 236181132 MDEwOlJlcG9za… livr… curso-r/… FALSE curso-r 10060716
9 9 311969160 MDEwOlJlcG9za… chess curso-r/… FALSE curso-r 10060716
10 10 154844030 MDEwOlJlcG9za… auth0 curso-r/… FALSE curso-r 10060716
# … with 294 more rows, and 100 more variables: owner_node_id <chr>,
# owner_avatar_url <chr>, owner_gravatar_id <chr>, owner_url <chr>,
# owner_html_url <chr>, owner_followers_url <chr>, owner_following_url <chr>,
# owner_gists_url <chr>, owner_starred_url <chr>,
# owner_subscriptions_url <chr>, owner_organizations_url <chr>,
# owner_repos_url <chr>, owner_events_url <chr>,
# owner_received_events_url <chr>, owner_type <chr>, …
Vamos fazer mais uma etapa de organização dos dados: são muitas colunas, e não precisaremos de todas para terminar o post. Também filtramos a base para remover os forks, já que não seriam repositórios da Curso-R originalmente.
df_repos_cursor <- lista_repos |>
dplyr::filter(fork == FALSE) |>
dplyr::select(
name,
created_at,
default_branch
) |>
dplyr::mutate(
data_criacao = readr::parse_datetime(created_at),
ano_criacao = as.Date(lubridate::floor_date(data_criacao, "year"))
)
Exemplo de visualização com os dados obtidos!
Em 2020, o Caio escreveu um post sobre o uso do termo ‘master’ no GitHub. Lá no post é explicado sobre a questão da substituição do termo ‘master’. Em 2020 a GitHub anunciou que faria a transição para o termo main (principal), e desde então muitas pessoas e organizações estão renomeando a branch principal de seus repositórios para ‘main’(inclusive existe um post no blog da RStudio sobre isso).
Usando os dados obtidos nesse post, vamos explorar os repositórios da Curso-R e averiguar qual é o nome da branch principal dos repositórios ao longo do tempo?
library(ggplot2)
main_percent <- mean(df_repos_cursor$default_branch == "main")
main_percent <- scales::percent(main_percent)
df_repos_cursor |>
dplyr::count(ano_criacao, default_branch) |>
ggplot() +
geom_col(aes(y = n, x = ano_criacao, fill = default_branch)) +
theme_bw() +
scale_x_date(date_labels = "%Y", date_breaks = "1 year") +
scale_fill_brewer(palette = "Pastel1") +
labs(x = "Ano de criação", y = "Número de repositórios", fill = "Nome da Branch")
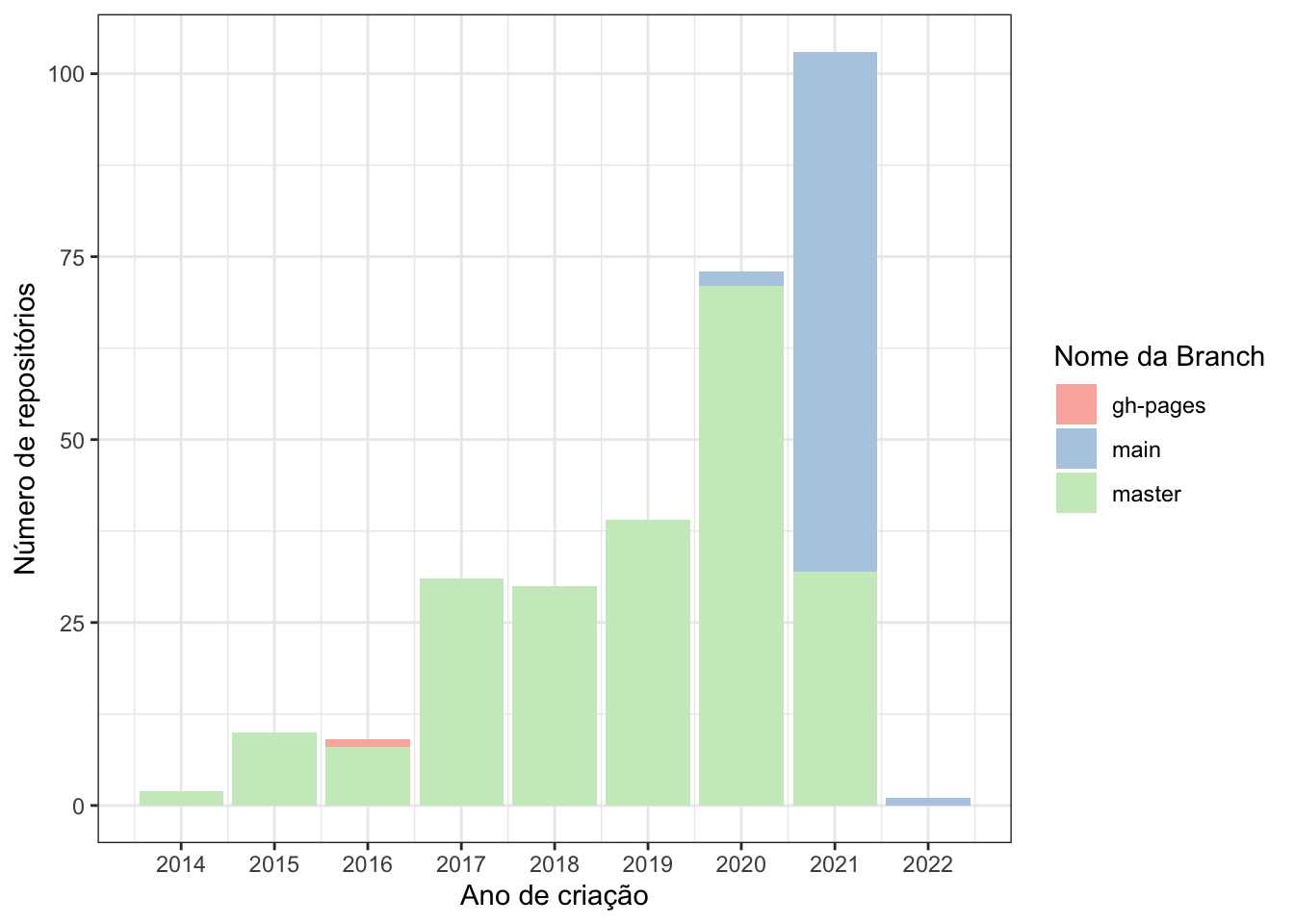
É possível ver que em 2021 o uso do termo ‘main’ para nomear as branches principais foi muito mais usado! Atualmente, o percentual de repositórios main é de 25% e esperamos que isso aumente com o tempo. Outra coisa legal do gráfico é ver como a criação de repositórios na organização da Curso-R foi crescendo ao longo do tempo!
É isso! Dúvidas, sugestões e críticas, mande aqui nos comentários. Postem também quais exemplos, dentre os que foram listados, vocês gostariam de saber mais!!
Se você quiser saber mais sobre acessar APIs, o curso de Web Scraping é uma ótima oportunidade!
Até a próxima!
Referências
Licença de uso

Estes materiais são disponibilizados com a licença Creative Commons Atribuição-CompartilhaIgual (CC BY-SA), ou seja, você pode compartilhar e adaptar este material, porém deve atribuir os créditos para as pessoas autoras, adicionando um link para o material original, e o seu material também deve ter este mesmo tipo de licença.
Saiba mais em: Creative Commons